Ruby z napędem odrzutowym - o kompilacji słów kilka
Maszyna wirtualna to za mało
Czytelnicy tego bloga dobrze znają i cenią sobie zalety języka Ruby. Wysoka ekspresywność, zwięzła składnia, dynamiczne dopisywanie metod, mechanizmy refleksji i ogromna, aktywna społeczność to tylko niektóre z nich. Niestety w życiu nic nie ma za darmo. Ruby to niemal przysłowiowy przykład języka o bardzo niskiej wydajności. Zmiany wprowadzone w wydaniu 1.9 poprawiły w pewnym stopniu szybkość wykonania ale nie przyniosły rewolucji. MRI nadal zajmuje ostatnie miejsca w rankingach wydajności różnych języków programowania.
Na przestrzeni ostatnich lat podejmowano różne próby poradzenia sobie z tym problemem. Jako przykład należy wskazać aktywnie rozwijany projekt JRuby, kompilujący Ruby to bytecode'u JVM. Podobne rozwiązanie zaproponował Microsoft przedstawiając projekt IronRuby oparty o .NET Framework. Własną maszynę wirtualną zaprojektowali autorzy Rubinius, którzy pracują nad implementacją Ruby wykorzystującą LLVM do kompilacji JIT.
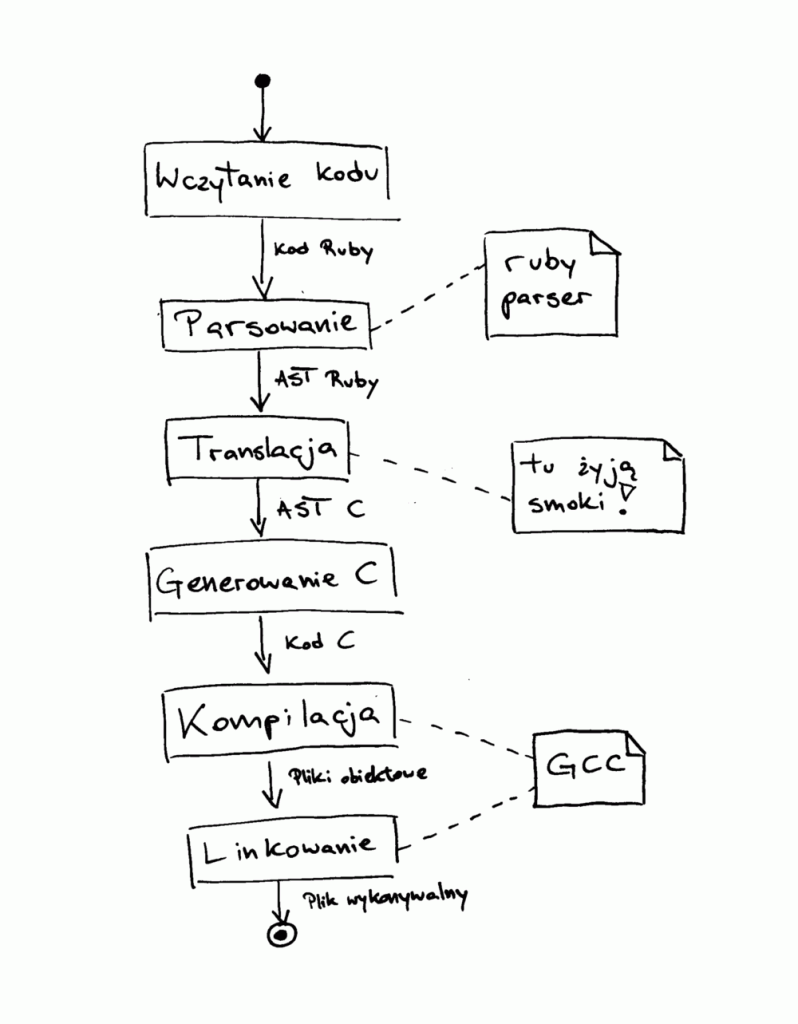
Wspólnie z Julianem Zubkiem, moim kolegą z wydziału, postanowiliśmy podejść do zagadnienia z innej strony. Spojrzeliśmy na przeciwległy koniec rankingów wydajności, gdzie dominują języki kompilowane do kodu maszynowego. Zdecydowaliśmy się stworzyć własną implementację Ruby tłumaczącą wejściowy kod do C. Wyjściowy kod miał być następnie kompilowany przez GCC lub inny kompilator do pliku wykonywalnego z natywnym kodem maszynowym.
Na dobrą sprawę jedyną cechą wspólną Ruby i C jest pisanie kodu od lewej do prawej i z góry na dół. Poza tym podobieństwem dzieli je przepaść. W C ze świecą szukać obiektowości, wyjątków, mechanizmów refleksji, automatycznego odśmiecania pamięci czy domknięć, w Ruby znanych jako bloki. Wyróżnia go jednak jedna istotna zaleta - powstały zeń kod maszynowy jest wyjątkowo szybki. Stąd nasza decyzja o wybraniu go jako język docelowy.
Przetwarzanie drzew
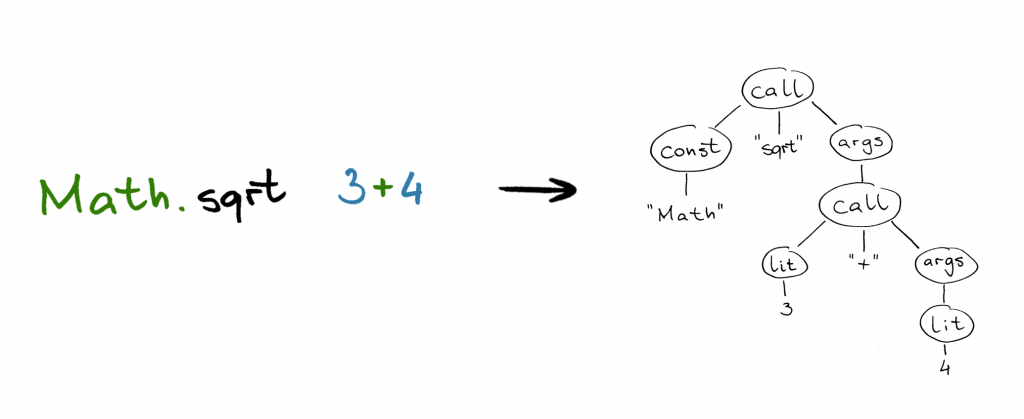
Nasz projekt został zaimplementowany w Ruby. Jego ogólna architektura jest dość prosta. Wejściowy kod w Ruby przetwarzamy przy pomocy gema ruby_parser uzyskując z niego tzw. AST, abstract syntax tree, czyli drzewiastą reprezentację struktury programu ułatwiającą dalszą manipulację. Otrzymane drzewo jest następnie przekazywane do serca naszego kompilatora, który analizuje je i stopniowo buduje z niego AST wyjściowego kodu C. Odpowiadający za to zadanie moduł to kluczowy element naszego projektu, w którym zawarta jest cała logika translacji. W oparciu o powstałe AST C generowany jest właściwy kod wyjściowy. Na koniec otrzymany kod jest kompilowany przez GCC i linkowany z zaimplementowanym przez nas skrawkiem biblioteki standardowej Ruby.
Moduł przetwarzający drzewo Ruby na drzewo C analizuje wejściowy kod w sposób naśladujący proces jego wykonania. Najpierw zapoznaje się z deklaracjami wszystkich klas i ich metod, ale nie analizuje od razu ich wnętrza. Analizę kodu wewnątrz danej metody rozpoczyna dopiero przy napotkaniu jej wywołania. Podejście to ma pewną istotną zaletę. Analizując metodę w momencie jej wywołania uzyskujemy wiedzę na temat typów przekazywanych do niej argumentów. Dzięki temu możemy poczynić pewne optymalizacje w kodzie wynikowym, które omówię w dalszej części artykułu.
Statyczna analiza całego kodu przed jego wykonaniem pozwala uzyskać wiele innych cennych informacji. Dzięki niej możemy ustalić na etapie kompilacji nazwy wszystkich zmiennych klasowych i instancyjnych. Jesteśmy też w stanie sprawdzić czy metody w obrębie danej klasy są nadpisywane lub czy klasa jest rozszerzana. Możemy też jednoznacznie przewidzieć typy obiektów, na które wskazywać będą poszczególne zmienne. Wszystkie te informacje są bardzo przydatne. Mogą być wykorzystane do zastąpienia wielu dynamicznych i - co za tym idzie - wolnych operacji statycznymi i szybkimi rozwiązaniami.
Do rzeczy, co działa?
Po trzech miesiącach prac nasz projekt wspiera strukturalną i obiektową składnię Ruby, nadpisywanie metod, proste bloki i odśmiecanie pamięci. Różnice między wejściowym a wyjściowym językiem wymusiły na nas zaimplementowanie powyższych wysokopoziomowych funkcjonalności w czystym C. Postaram się pokrótce przedstawić realizację każdej z nich.
Obiektowość Ruby została zrealizowana w C przy pomocy dostępnych w nim struktur i funkcji. Obiekty reprezentowane są jako struktury zawierające informację o swoim typie oraz wskaźniki na zawarte w nich pola. Pozwala na to analiza całego kodu na etapie kompilacji, w trakcie której jesteśmy w stanie ustalić wszystkie zmienne instancyjne w obrębie danej klasy.
Metody są realizowane jako funkcje, do których jako pierwszy argument przekazywany jest wskaźnik na obiekt self a następnie przekazywane są właściwe argumenty wywołania. Ze względu możliwość pominięcia w Ruby return na końcu ciała metody, nasz translator zapamiętuje ostatnie wyrażenie i automatycznie zwraca je z wynikowej funkcji w C. Dotyczy to też bardziej złożonych konstrukcji, jak choćby if na przykładzie wartości bezwzględnej:
def abs(x)
if x > 0
x
else
-x
end
end
W tym miejscu warto wspomnieć o innej ciekawej cesze Ruby. Poza nielicznym wyjątkami, każda instrukcja jest wyrażeniem, co na polski tłumaczy się jako ,,wszystko zwraca jakąś wartość''. Widać to na przykładzie powyższej metody abs. Zwraca ona wartość ostatniego wyrażenia, czyli if, który zwraca z kolei wartość ostatniego wyrażenia z jednej ze swoich odnóg. Cała ta funkcjonalność również musiała zostać sztucznie przeniesiona w C. Nasz kompilator zapamiętuje wartości zwracane przez wszystkie wyrażenia na wypadek konieczności zwrócenia lub wykorzystania ich na późniejszym etapie.
Bloki są traktowane podobnie jak metody. Każdy z nich jest tłumaczony do funkcji w C. Podczas wykonania, przed wywołaniem metody do której przekazujemy blok, umieszczamy odpowiadający mu wskaźnik na funkcję go na specjalnym stosie. Metoda wykorzystująca blok pobiera wskaźnik w momencie skorzystania z instrukcji yield. Dzięki rozwiązaniu ze stosem rozwiązanie pozwala na zagnieżdżone bloki, wszechobecne m.in. w testach utworzonych przy pomocy RSpeca. Obecna implementacja nie pozwala jeszcze na korzystanie ze zmiennych zdefiniowanych poza blokiem, ale jest to jedna z priorytetowych pozycji na naszej liście zadań do zrobienia.
Automatyczne odśmiecanie pamięci jest bardzo skomplikowanym zagadnieniem. Śledzenie wszystkich odwołań do obiektów, ustalanie, czy są nadal używane, czy też efektywne algorytmy zarządzania alokacją to tylko wierzchołek góry lodowej jaką stanowi utworzenie własnego garbage collectora. Na szczęście istnieją jednak gotowe rozwiązania, które rozwiązują ten problem.
W naszym projekcie wykorzystaliśmy Boehm GC -- dojrzałą bibliotekę pozwalającą na bardzo proste dołączenie automatycznego odśmiecania pamięci do swoich projektów w C. Dzięki temu cały proces zwalniania pamięci odbywa się w tworzonych przez nasz kompilator programach automatycznie i efektywnie, a my mogliśmy bez przeszkód poświęcić całą swoją uwagę procesowi translacji.
Metody po raz wtóry
Dynamiczne wiązanie metod, które pozwala między innymi na pisanie bardzo zwięzłych testów przy pomocy RSpeca, jest operacją wyjątkowo kosztowną. Przeanalizujmy proces wywoływania metody w Ruby. Najpierw musimy ustalić klasę obiektu. Następnie, znając typ, możemy sprawdzić w odpowiedniej strukturze danych, czy dana klasa ma metodę o zadanej nazwie. Jeśli nie, przechodzimy do nadklasy i powtarzamy procedurę aż do Object. W przypadku niepowodzenia wołamy method_missing. Jeśli uda nam się znaleźć odpowiednią metodę, możemy wreszcie przekazać do niej argumenty. Zainteresowanych szczegółami odsyłam do pliku vm_method.c w źródłach MRI.
Zwróćcie uwagę, że wspomniana struktura przechowująca informacje o metodach musi pozwalać na modyfikacje. Jak wiemy, w Ruby metody klas możemy zmieniać niczym rękawiczki, co każdorazowo wymusza naniesienie zmian w owej tablicy. Stawiając wymaganie możliwości rozszerzania i modyfikowania tablicy metod musimy liczyć się z tym, że odbije się to na wydajności operacji przeszukiwania.
Zastanówmy się teraz co możemy zyskać przy pomocy statycznej analizy kodu dokonywanej przez nasz kompilator. Zakładając, że nie użyta zostanie metoda send lub eval, jesteśmy w stanie ustalić nazwy wszystkich metod danej klasy. Jeśli nie miały miejsca żadne nadpisania, możemy nawet na etapie kompilacji przypisać poszczególnym nazwom konkretne funkcje w C. Zysk jest oczywisty. Zamiast całej przedstawionej wyżej procedury wywołanie metod sprowadza się do wykonania funkcji C.
Powyższej optymalizacji nie można zastosować we wszystkich przypadkach. Bardzo często nie potrafimy w czasie kompilacji ustalić typu danej zmiennej. Przykład takiej sytuacji to metoda, która w pewnych warunkach zwraca nil a w innych obiekt String. W takim wypadku musimy zastosować inną strategię. Na etapie kompilacji zapisujemy w pliku wynikowym strukturę danych pozwalającą na możliwie szybkie skojarzenie typu i nazwy metody ze wskaźnikiem na funkcję C. Dodatkowe informacje uzyskane na etapie kompilacji pozwalają nam na poczynienie w tym miejscu kolejnych usprawnień.
Zauważmy, że biorąc pod uwagę znajomość nazw wszystkich metod podczas translacji, struktura przechowująca metody nie musi wspierać operacji dodawania. Jest tworzona tylko raz, podczas kompilacji, a na późniejszym etapie nie potrzebujemy dodawać do niej nowych elementów. Stawiamy przed nią tylko dwa wymagania. Po pierwsze, ma pozwalać na bardzo szybkie znajdowanie elementów - funkcji - po kluczu - nazwie metody - a po drugie ma pozwalać na nadpisanie wartości przypisanej kluczowi w razie nadpisania metody wewnątrz klasy.
Okazuje się, że wymagania te pozwalają nam na wykorzystanie struktury o lepszych właściwościach od drzewa czy tablicy z haszowaniem. Do przechowywania informacji o metodach stosujemy tzw. perfekcyjne tablice z haszowaniem. Nie chcę w tym miejscu rozpoczynać szczegółowego opisu tych struktur - zainteresowanych odsyłam na Wikipedię. Podkreślę tylko, że podobnie jak tradycyjne tablice z haszowaniem struktury te zapewniają nam dostęp w czasie stałym. Na ich korzyść świadczy brak kolizji, zagwarantowany przez funkcję haszującą zoptymalizowaną pod kątem zadanego zestawu kluczu, który w naszym wypadku jest zbiorem nazw metod danej klasy.
Połączenie wyszukiwania metod w perfekcyjnych tablicach z haszowaniem ze statycznym wywoływaniem funkcji tam, gdzie jest to możliwe, pozwala nam na osiągnięcie zdecydowanego zysku w porównaniu z MRI. Wynik ten da się jeszcze poprawić przy pomocy cache'owania wyników przeszukiwania tablic metod lub zastosowania w ich miejsce tradycyjnych tablic C. Jest to jedno z głównych zagadnień, któremu chcemy stawić czoła w trakcie dalszego rozwoju naszego projektu.
Wyniki i plany na przyszłość
Mógłbym dalej mnożyć przykłady ciekawych cech Ruby, których translacja do C nie była oczywista. Każda z nich stanowiła dla nas ciekawe zadanie wymagające przemyślenia i eksperymentów z różnymi podejściami. Czas jednak nagli, a ja nie przedstawiłem jeszcze wyników.
Poza garniturem testów funkcjonalnych weryfikujących poprawność naszej implementacji w porównaniu z Ruby 1.9.2 przygotowaliśmy kilka testów wydajnościowych. Są to proste, akademickie testy, jak choćby mnożenie macierzy, dwa różne sortowania, operacje na liczbach zmiennoprzecinkowych czy test głębokiej rekurencji przy pomocy funkcji Ackermanna. Uruchomiliśmy je na naszej implementacji oraz porównaliśmy ich czas wykonania z wynikami osiągniętymi przez Ruby 1.9.2.
W kilku spośród powyższych testów uzyskaliśmy zdecydowaną, niemal pięciokrotną przewagę. Były jednak przypadki, w których to MRI osiągnęło lepsze wyniki. Motywuje nas to do dalszej pracy, tym bardziej, że mamy jeszcze wiele pomysłów na dalsze usprawnienia i optymalizacje.
Wyniki profilowania testów pokazały, że koszt dynamicznego wołania metod przy braku znajomości typu obiektu jest dość wysoki. Podczas dalszych prac mamy zamiar skupić się na rozwiązaniach, które pozwoliłyby go zredukować. Poza optymalizacją mechanizmów wyszukiwania odpowiednich funkcji do wywołania, kluczowe jest tutaj uzyskanie na etapie translacji jak najwięcej informacji o typach obiektów, których metody wołamy. Zysk wydajności można by uzyskać na przykład ustalając typy obiektów przechowywane w kolekcjach takich jak Array czy Hash. Śledząc wszystkie operacje wykonywane na tych strukturach moglibyśmy stwierdzić, że niektóre z nich przechowują obiekty tylko jednego typu, np. String, co pozwoliłoby na przyspieszenie wołania ich metod.
Poza próbami wyciśnięcia z generowanego przez nas kodu jak najlepszych wyników musimy również zabrać się ze implementację niewspieranych jeszcze cech Ruby. Przykłady to m.in. system wyjątków, moduły, lambdy i praca nad biblioteką standardową. Mamy już pomysł na implementację niektórych spośród tych funkcjonalności, jak np. wyjątków czy modułów, więc już wkrótce powinny zostać dodane do listy obsługiwanych przez nasz kompilator elementów Ruby. Z drugiej strony wielowątkowość jest bardzo skomplikowanym zagadnieniem, którego obsługa niesie za sobą konieczność wielu kosztownych zmian w naszym projekcie, zarówno z punktu widzenia czasu programisty jak i czasu wykonania wyjściowych programów.
Obecnie staramy się doprowadzić nasz kod do stanu, w którym będziemy mogli bez obciachu pochwalić się nim przed społecznością. Tu i ówdzie potrzeba refaktoringu, przyda się napisać trochę dokumentacji. Poza tym czeka nas wybór licencji. Nadal nie mamy też nazwy dla projektu - pomysły mile widziane. Liczymy na to, że projekt uda się opublikować w drugim kwartale tego roku.
Cały czas zastanawiamy się w którą stronę skierować nasz projekt. Czy ma być to kolejna implementacja Ruby? Czy też jedynie narzędzie pozwalające na statyczną kompilację wybranych fragmentów projektów w Ruby w celu ich przyspieszenia, co zaproponował Tomasz Stachewicz? Jesteśmy otwarci na pomysły. Bardzo chętnie poznamy opinie i pomysły czytelników.